
GPT‑5, a fondo
Hemos vuelto con episodio especial de verano dedicado a GPT-5 su presentación, números, recibmiento y nuestra experiencia.

Hemos vuelto con episodio especial de verano dedicado a GPT-5 su presentación, números, recibmiento y nuestra experiencia.
Os dejamos apuntes clave sobre el nuevo modelo de OpenAI
La foto general. GPT‑5 no es un único modelo sino un sistema: un “main” rápido para la mayoría de peticiones, un “thinking” que dedica cómputo a los casos difíciles y un router en tiempo real que decide cuál usar en ChatGPT. Cuando agotas tu cupo, te reenvía a versiones mini (y en API existe también nano). Con una instrucción explícita (“think hard about this”) puedes forzar el razonamiento; además, los suscriptores de pago pueden seleccionar “GPT‑5 Thinking” en el selector de modelos. Simplifican, pero no mucho.
Menos alucinaciones. Con búsqueda web activada, GPT‑5 comete ~45 % menos errores factuales que GPT‑4o y, en modo thinking, ~80 % menos que OpenAI o3. En ensayos de “engaño” (p. ej., afirmar que vio imágenes que no existían) GPT‑5 thinking reduce la tasa frente a o3. Recordemos que o3 era un modelo que avanzó mucho en algunas tareas pero que alucinaba bastante.

Sycophancy a la baja. OpenAI entrenó post‑training para recortar la adulación; las nuevas “personalidades” ayudan a modular el tono. Un análisis de este aspecto en Error500.

Benchmarks donde sube. OpenAI reporta AIME‑2025 94,6 % (sin herramientas), SWE‑bench Verified 74,9 %, Aider Polyglot 88 % (pass@2), MMMU 84,2 %, y HealthBench Hard 46,2 %; GPT‑5 Pro es SOTA en GPQA sin herramientas. Sólo publican comparativas con sus modelos anteriores (véase System Card), pero reflejan mejoras en escritura, código y temas de salud.
Benchmarks contra otros:
Chatbot Arena (LMSYS). En el WebDev Arena, GPT‑5 aparece en lo alto, y en el Text arena compite en el grupo de cabeza sin despegarse del todo. Buenas señales, pero sin dominio aplastante. Véase LMArena.
ARC‑AGI‑2. GPT‑5 no destaca: François Chollet señala 9,9 % para GPT‑5 (sin herramientas) frente a 15,9 % de Grok 4 Heavy. Reddit
HLE (Humanity’s Last Exam). GPT‑5 Pro obtiene un ~42 % con herramientas, por detrás de Grok 4 Heavy (44,4 %).
Autonomía (METR). El “time horizon” al 50 % de GPT‑5 thinking es ≈ 2 h 15 m (IC95 % 65 m–4 h 30 m), superior a o3 (1 h 30 m). Es una estimación de cuánto trabajo humano (en tiempo) logra completar como agente con herramientas.
En ingeniería de software y salud hay mejoras claras; en “razonamiento general” tipo ARC‑AGI‑2, el salto no es decisivo. ¿La apuesta por el router? Sam Altman defiende que el uso diario de modelos de razonamiento subió con GPT‑5: de < 1 % a 7 % en usuarios gratis y de 7 % a 24 % en Plus.
Pero a la vez las primeras experiencias fueron muy negativas. OpenAI defiende que la culpa fue un fallo en el funcionamiento del router
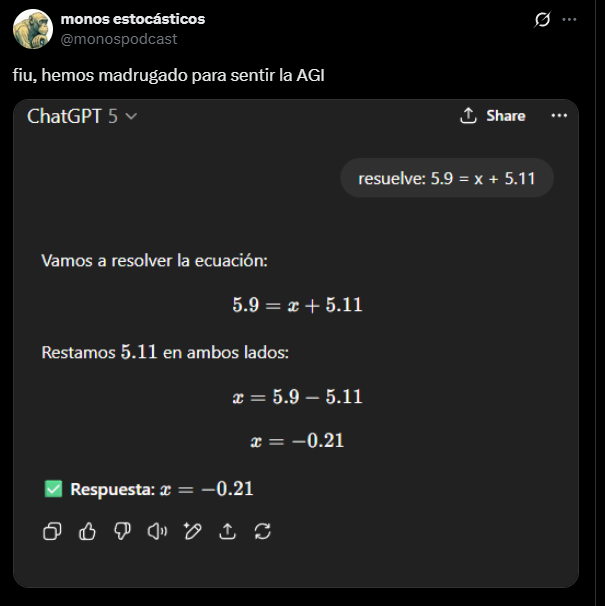
Además han recuperado el 4o para usuarios de pago y han cambiado las condiciones iniciales que empeoraban la calidad de los modelos y/o cantidad de mensajes con los mejores:
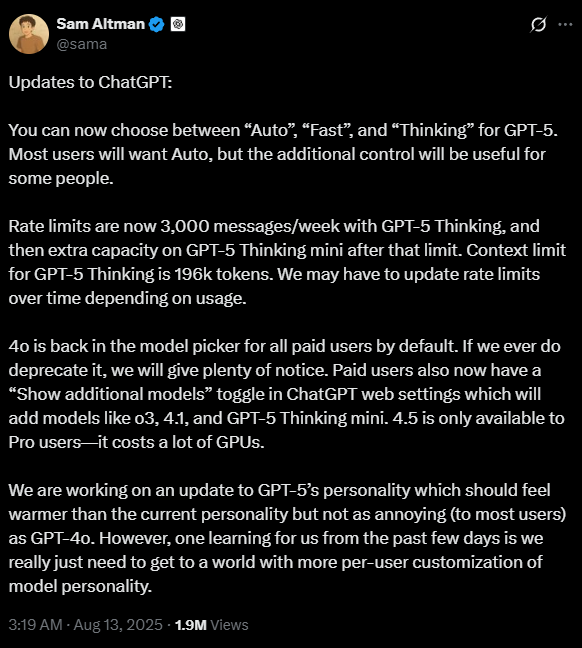
Nuestras Recomendaciones prácticas
Si escribes o investigas: cuando quieras menos floritura y más rigor factual, activa Thinking (“think hard about this”) o usa GPT‑5 Pro si lo tienes; verás más no‑sabe y menos invención.
Si programas: usa Thinking en tareas con múltiples pasos (p. ej., parches SWE‑bench‑like, refactors amplios). Si el router te baja a mini, fuerza el modo Thinking o cambia al modelo Thinking explícito.
Si eres power user: revisa en cada sesión qué modelo te ha respondido y no dudes en fijar manualmente Thinking cuando la tarea lo justifique. Aprovecha los modos Auto/Fast/Thinking para decidir latencia vs. calidad.
API: planifica cómputo y coste con el presupuesto 400 K/128 K y precios por millón de tokens ($1,25 entrada / $10 salida en gpt‑5; mini y nano más baratos). Evita plantillas que saturen salida si no son necesarias.
Veredicto
¿Es buen modelo? Sí. ¿Es un salto cuántico? No. GPT‑5 mejora a 4o y o3 donde importa a muchos profesionales (escritura con menos alucinación, código más robusto, salud más segura) y unifica el uso con un router que, cuando funciona, reduce fricción. Pero la experiencia percibida depende del enrutado: si te cae main cuando esperabas thinking, sentirás bajón.